
Die ganzheitliche Data-Suite von TimeXtender
Sie wurde entwickelt, um die Flexibilität und Skalierbarkeit zu bieten, die für die dynamischen und komplexen Datenökosysteme von heute erforderlich sind. Von der Automatisierung von Datenintegrationsprozessen bis hin zur Anwendung strenger Governance-Standards für alle Datenbestände – unsere umfassende Suite adressiert die vielfältigen Herausforderungen, denen sich Unternehmen bei der effektiven Verwaltung ihrer Daten gegenübersehen.

Data Integration
Aufbau einer Dateninfrastruktur, die in der Lage ist, saubere und zuverlässige Daten zu erfassen, aufzubereiten und zu liefern.

Master Data Management
Sicherstellung der Einheitlichkeit, Genauigkeit und Verwaltung der wichtigsten Geschäftsdaten in verschiedenen Systemen.

Data Quality
Schaffen Sie Vertrauen in Ihre Daten und halten Sie hochwertige Datenstandards für alle Ihre Datenbestände ein.

Orchestration
Führen Sie jeden Schritt auf Ihrer Datenreise effizient aus, unabhängig von den beteiligten Systemen und Plattformen.
A Single Source of Truth
TimeXtender vereinfacht die Datenverwaltung und macht Daten für Unternehmen aller Branchen zugänglich und nutzbar.
TimeXtender bietet alle Funktionen, die Sie benötigen, um eine robuste, sichere und dennoch agile Dateninfrastruktur für Analysen und KI auf die schnellstmögliche und effizienteste Weise aufzubauen – und das alles mit einer einzigen Benutzeroberfläche mit wenig Code.

Welche Rolle spielen Low-Code- und No-Code-Plattformen?
Agile Datensammlung und Datenaufbereitung in Unternehmen
Kann ein Anwender ohne tiefgreifende Programmierkenntnisse selbstständig mittels Low-Code- bzw. No-Code-Plattformen Daten aufbereiten und zur Verfügung stellen? Wie sieht der heutige Prozess „From Raw To Ready“ aus, und wo liegen die Grenzen von Data-Warehouse-Automatisierungsplattformen? Dieser Artikel gibt einen Überblick, in welchen Szenarien sich Low-Code- und No-Code-Plattformen erfolgreich einsetzen lassen und was es zu beachten gilt.
BI-SPEKTRUM März 2023
Autor: Andreas Melzer
TimeXtender – Modern Data Estate Builder
Denken Sie an Ihre letzten Daten- und Analyseprojekte im Unternehmen: Wie viel Prozent der Gesamtzeit wurde für die Suche und Aufbereitung der Daten aufgewendet, verglichen mit der Zeit, die Sie für Visualisierung, Berichterstattung oder Analyse genutzt haben?
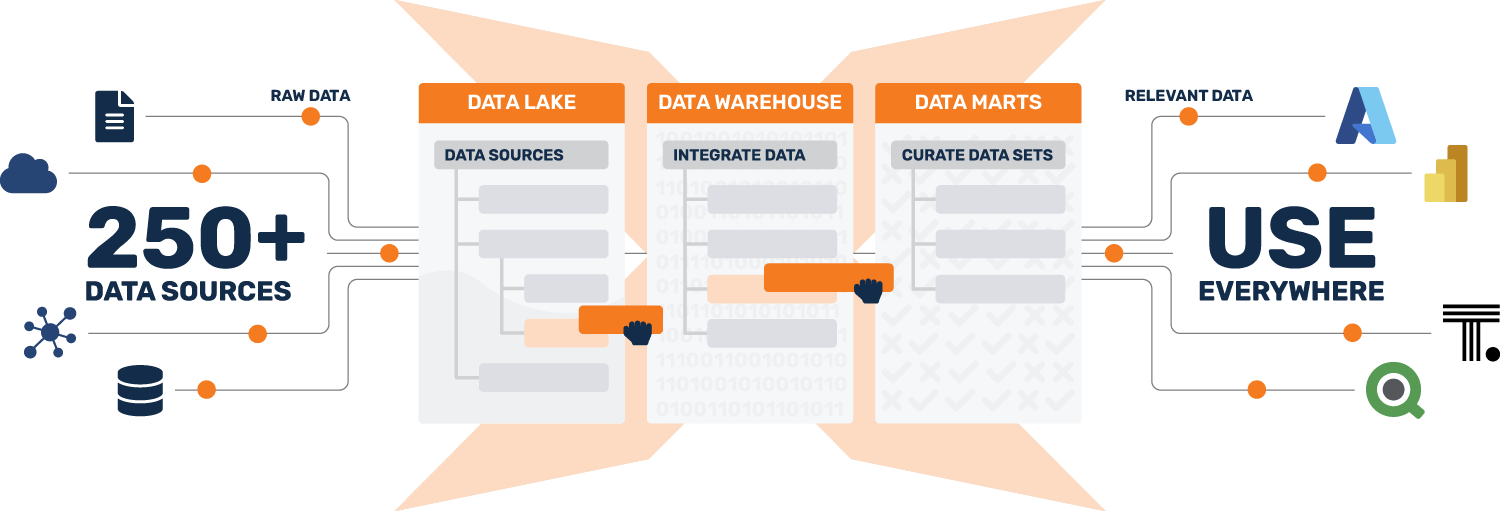
Ganzheitliche Datenintegration mit 3 modularen Komponenten:
Durch die Nutzung von Metadaten zur Vereinheitlichung der einzelnen Ebenen des Datenstapels und zur Automatisierung manueller Prozesse ermöglicht TimeXtender eine 10-mal schnellere Aufnahme, Aufbereitung und Bereitstellung geschäftsfähiger Daten und senkt gleichzeitig Ihre Kosten um 70-80 %. Unser modularer Ansatz und die Cloud-basierten Instanzen geben Ihnen die Freiheit, diese Komponenten separat (z. B. einen einzelnen Data Lake) oder alle zusammen als vollständige und integrierte Datenlösung aufzubauen.
Konsolidieren Sie Rohdaten in einem zentralen Data Lake.
Auf der Ingestion-Ebene konsolidiert TimeXtender Rohdaten aus unverbundenen Quellen in einem zentralisierten Data Lake oder Lakehouse. Diese Rohdaten werden häufig in Data-Science-Anwendungsfällen verwendet, z. B. zum Trainieren von Machine-Learning-Modellen für erweiterte Analysen.
- Einfaches Konsolidieren von Daten aus unverbundenen Quellen: Erfassen und kombinieren Sie Rohdaten aus potenziell Hunderten von Quellen mit minimalem Aufwand in einem zentralisierten Data Lake.
- Universelle Konnektivität: TimeXtender bietet ein Verzeichnis von über 250 vorgefertigten, vollständig verwalteten Datenkonnektoren mit zusätzlicher Unterstützung für beliebige benutzerdefinierte Datenquellen.
- Automatisieren Sie Ingestion-Aufgaben: Definieren Sie den Umfang (welche Tabellen) und die Häufigkeit (den Zeitplan) der Datenübertragungen für jede Ihrer Datenquellen. Die Ingestion-Schicht lernt aus früheren Ausführungen und kann dann automatisch Objektabhängigkeiten einrichten und pflegen, das Laden von Daten optimieren und Aufgaben orchestrieren.
- Beschleunigung von Datenübertragungen durch inkrementelles Laden: TimeXtender bietet die Möglichkeit, nur die neu erstellten oder geänderten Daten zu laden, anstatt den gesamten Datensatz. Da weniger Daten geladen werden, können Sie die Verarbeitungszeiten erheblich verkürzen und die Aufnahme, Validierung und Umwandlung von Aufgaben beschleunigen.
- Keine kaputten Pipelines mehr: TimeXtender bietet einen intelligenteren und automatisierten Ansatz für die Verwaltung von Datenpipelines. Sobald eine Änderung an Ihren Datenquellen oder Systemen vorgenommen wird, können Sie mit TimeXtender diese Änderungen mit nur wenigen Klicks sofort in die gesamte Pipeline übertragen – kein manuelles Debuggen und Reparieren defekter Pipelines mehr.
Bereinigung, Validierung, Anreicherung, Umwandlung und Modellierung der Daten.
In der Vorbereitungsschicht werden die Daten bereinigt, validiert, angereichert, umgewandelt und zu einer „einzigen Version der Wahrheit“ in Ihrem Data Warehouse modelliert.
- Umwandlung von Rohdaten in eine einzige Version der Wahrheit: Wählen Sie Rohdaten aus der Ingestion-Ebene aus, bereinigen, validieren und reichern Sie diese Daten an, und definieren Sie dann Transformationen und führen Sie sie aus. Nach Abschluss dieses Datenaufbereitungsprozesses können Sie Ihre bereinigten, zuverlässigen Daten in dimensionale Modelle übertragen, um eine einzige Version der Wahrheit“ für Ihr Unternehmen zu erstellen.
- Leistungsstarke Datentransformationen mit minimaler Codierung: Ganz gleich, ob Sie einfach nur eine Zahl von positiv in negativ ändern oder komplexe Berechnungen mit vielen Feldern in einer Tabelle durchführen, TimeXtender macht den Datenumwandlungsprozess einfach und leicht. Alle Transformationen können innerhalb unserer Low-Code-Benutzeroberfläche durchgeführt werden, wodurch das Schreiben von komplexem Code überflüssig wird, das Fehlerrisiko minimiert und der Transformationsprozess drastisch beschleunigt wird. Diese Transformationen können noch leistungsfähiger gemacht werden, wenn sie mit Bedingungen, Datenauswahlregeln und bei Bedarf mit benutzerdefiniertem Code kombiniert werden.
- Ein moderner Ansatz für die Datenmodellierung: Mit unserer Vorbereitungsschicht können Sie ein hochgradig strukturiertes und organisiertes Repository mit zuverlässigen Daten aufbauen, um Business Intelligence- und Analyseanwendungen zu unterstützen. Sie beginnt mit dem traditionellen „Sternschema“, fügt aber zusätzliche Tabellen und Felder hinzu, die den Datenkonsumenten wertvolle Einblicke bieten. Aus diesem Grund ist die Vorbereitungsschicht einfacher zu verstehen und zu verwenden.
Erstellen Sie Data Marts, die nur die relevante Teilmenge von Daten liefern.
Die Bereitstellungsschicht bietet Ihrem gesamten Unternehmen eine vereinfachte, konsistente und geschäftsfreundliche Sicht auf alle Datenprodukte, die Ihrem Unternehmen zur Verfügung stehen. Diese semantische Schicht maximiert die Datenerkennung und -verwendung, stellt die Datenqualität sicher und bringt technische und nicht-technische Teams auf eine gemeinsame Datensprache.
- Maximierung der Datennutzbarkeit: Die Vorbereitungsschicht kann verwendet werden, um technischen Datenjargon in vertraute Geschäftsbegriffe wie „Produkt“ oder „Umsatz“ zu übersetzen und so eine gemeinsame „semantische Schicht“ zu schaffen. Diese Schicht bietet Ihrem gesamten Unternehmen eine vereinfachte, konsistente und geschäftsfreundliche Ansicht aller verfügbaren Daten, was die Datenerkennung und -verwendung maximiert, die Datenqualität sicherstellt und technische und nicht-technische Teams auf eine gemeinsame Datensprache einstellt.
- Höhere Agilität mit Data Marts: Die Bereitstellungsschicht ermöglicht es Ihnen, abteilungs- oder zweckspezifische Modelle Ihrer Daten zu erstellen, die oft als „Data Marts“ bezeichnet werden. Diese Data Marts stellen jeder Abteilung oder Geschäftseinheit nur die relevantesten Daten zur Verfügung, was bedeutet, dass die Mitarbeiter keine Zeit mehr damit verschwenden müssen, alle berichtspflichtigen Daten im Data Warehouse zu durchsuchen, um das zu finden, was sie brauchen.
- Bereitstellung für Visualisierungstools Ihrer Wahl: Semantische Modelle können für Visualisierungstools Ihrer Wahl (wie PowerBI, Tableau oder Qlik) bereitgestellt werden, um Dashboards und Berichte schnell zu erstellen und flexibel zu ändern. Da semantische Modelle innerhalb von TimeXtender erstellt werden, liefern sie immer konsistente Felder und Zahlen, unabhängig davon, welches Visualisierungstool Sie verwenden. Dieser Ansatz verbessert die Datenverwaltung, -qualität und -konsistenz drastisch und stellt sicher, dass alle Benutzer eine einzige Version der Wahrheit verwenden.
Master Data Management
für: CFO | Application Manager | Data Team | BI Team
Nutzen:
Das „Easy Data Management“ von TimeXtender ermöglicht es Unternehmen, ihre täglichen Aufgaben im Datenmanagement nahtlos und einfach zu erledigen. Das Feature verbessert die Zusammenarbeit zwischen IT und Business, da Anwendungsfälle im Datenmanagement oft Wissen aus beiden Bereichen erfordern.
Die IT oder das BI-Team erstellt ein einfaches Datenmodell, während die richtigen Fachanwender die Daten pflegen und anreichern.
TimeXtender bietet hierfür einzigartige Schnittstellen sowohl für IT und BI-Team als auch für die Fachanwender.
Darüber hinaus bietet „Easy Data Management“ Unternehmen ein Master Data Management (MDM), das von der Verwaltung von Daten in lokalen Excel-Tabellen zu einfachen, zentral verwalteten Lösungen übergeht.
Vorteile
- Mapping und Pflege lokaler SKUs in regionalen/globalen Strukturen
- keine Abhängigkeit von lokalen Excel-Tabellen, da diese in zentral verwaltete Datenlösung umgewandelt werden
- Vermeidung von Excel oder anderen unpassenden Tools für das Mapping oder Datenanreicherung
- einfache Erweiterung von Datensätzen mit zusätzlichen Hierarchien
- Verwaltung aller KPIs oder anderen Daten im Easy Data Management
Vorteile
- schnelle Implementierung neuer Datenqualitätskontrollen mithilfe eines flexiblen Regel-Designers
- Einsicht in Datenqualität zentral an einem Ort sorgt für mehr Transparenz
- Festlegung von Regeln, Einsichtsberechtigungen, Revisionsprotokolle u.v.m.
- Überwachung & Analyse der Datenqualität durch Verfolgung von Datenqualitätsproblemen und Erstellung von Berichten über Daten-KPIs
- kontinuierliche Überwachung von Geschäftsprozessen, um Datenprobleme effektiv anzugehen und Prozesse stetig zu optimieren
Data Quality Control, Monitoring & Governance
für: CFO | Data Governance | Business Unit Managers
Nutzen:
Die Data-Governance-Komponente von TimeXtender wurde entwickelt, um das Vertrauen in Daten zu stärken und die Genauigkeit von BI, Berichten und Entscheidungsfindung zu verbessern.
Sie erhalten Kontrolle über Ihre Daten und können verhindern, dass schlechte Daten in Ihre Systeme gelangen.
Die Datenqualität lässt sich gezielt überwachen und mit minimalem Aufwand proaktiv validieren und verbessern.
Sie haben die Möglichkeit, schnell und effektiv auf neue Datenherausforderungen zu reagieren. Nur so können Sie das Vertrauen und die Qualität Ihrer Daten kontinuierlich zu verbessern, um die betriebliche Effizienz zu steigern und betriebliche Risiken zu minimieren.
Data Process Orchestration & Visual Data Quality
für: Data Team | CIO | CFO
Nutzen:
Hiermit können Unternehmen ihre ETL-Prozesse (Extrahieren, Transformieren, Laden) nahtlos über verschiedene technologische Umgebungen hinweg verwalten – einschließlich lokaler, hybrider und Cloud-Systeme.
Geboten wird hierbei eine zentrale Stelle für die Orchestrierung, Planung und Ausführung von Daten über verschiedene Technologien hinweg. Mit dieser umfassenden Lösung können Unternehmen ihr gesamtes Datenpipeline-Management auf einer einzigen Plattform konsolidieren. Sie bietet die Möglichkeit, Datenflüsse visuell zu analysieren und zu verwalten, Datenqualitätskontrollen direkt in diese Flüsse zu integrieren und einen durchgängig orchestrierten Prozess sicherzustellen, der alle Lücken in der Datenpipeline effektiv schließt.
Dieser proaktive Ansatz ermöglicht eine frühzeitige Erkennung von Problemen. Darüber hinaus bieten die integrierten Mess- und Berichtsfunktionen den Anwendern eine bequeme Visualisierung von Datendiskrepanzen mit dem Ampelsystem von Exmon oder mit den bevorzugten Analysetools wie Power BI, Qlik oder Tableau.
Vorteile
- Sicherstellung einer hohen Qualität der Datenpipeline
- Vermeidung von Zeitverlusten und Unsicherheiten bei Planung & Ausführung von technologieübergreifenden Datenpipelines
- einfache Verwaltung von Pipelines über verschiedene Technologien & Umgebungen hinweg
- weniger Verzögerung bei Pipeline-Prozessen aufgrund festgestellter schlechter Datenqualität
- Reduzierung des Zeitaufwands bei Fehlersuche dank intelligenter Fehlerbehebung
- Transparenz über Datenprozesse
- Self-Service-Pipeline-Ausführung für bestimmte Geschäftsanwender & -prozesse möglich
Besseres Datenmanagement durch Datenautomatisierung und Datenmodellierung
TimeXtender schließt durch die Automatisierung aller nur möglichen zu automatisierenden Prozesse im Data-Warehouse-Lebenszyklus sämtliche Datenlücken. Die vollständig integrierte Metadaten-Engine bietet Funktionalitäten wie Datenabfolge, Auswirkungsanalyse, langsam wandelnde Dimensionen, automatisierte Dokumentationserstellung, intelligente Adapter, geplante Ausführung und vieles mehr.
![]()
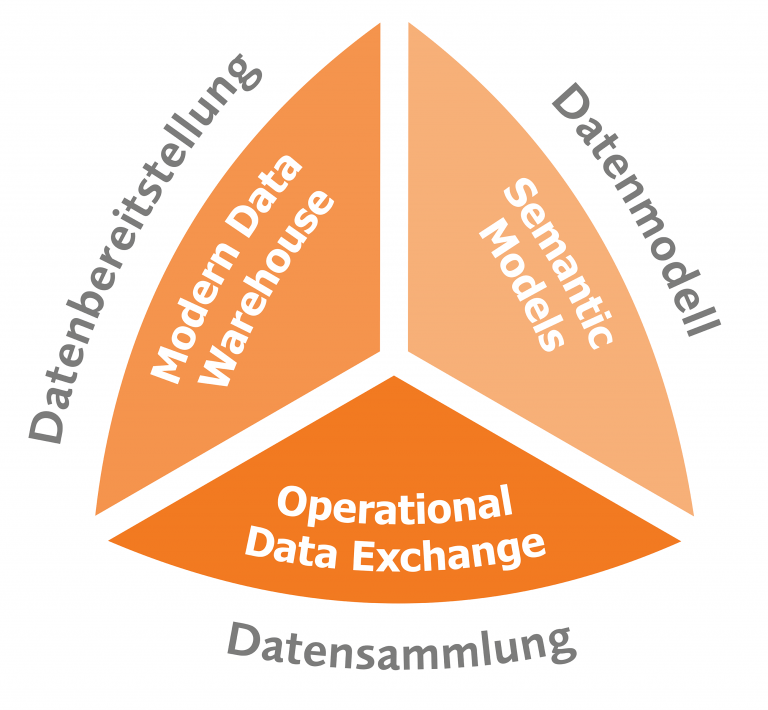
Modern Data Estate Management
TimeXtender ermöglicht Geschäftsführern und Entscheidungsträgern, einen schnellen Zugriff auf ihre Daten und stellt dadurch verlässliche Analysen bereit. Mühsame und zeitaufwendige Datenvorbereitungen können ganz einfach automatisiert werden.
Mit der Data-Management-Plattform für Data Goverance und Self-Service-BI sind Datenmodelle, Tabellen, Felder und Nutzerrollen jederzeit nachvollziehbar.
TimeXtender wird vollständig in Qlik® integriert und spart so mit weniger Ressourcen zusätzlich enorm Zeit ein.
Wie funktioniert der Data Estate Builder?
Semantic Models
Durch automatisierte Qlik® Modelle erhalten Sie einfachen Zugriff auf die Daten, die Sie am meisten interessieren.
Der Semantic Layer unterstützt die Bereitstellung spezifischer Datenmodelle, so dass auch gelegentliche Anwender datengesteuerte Entscheidungen treffen können. Mit dem in TX DWA eingebauten Qlik® Modeler und Script Generator können Sie Qlik® Modelle entwerfen, ohne eine einzige Codezeile zu schreiben. Dies ermöglicht eine schnelle Erstellung und flexible Änderung von Präsentationen, so dass mehr Business-Anwender selbstständig ihre eigenen Daten entdecken und Erkenntnisse gewinnen können.
Vorhandene Modelle können sofort für die Verwendung in einem anderen Front-End übersetzt werden.
Modern Data Warehouse
Verlässliche Datenquellen für mehr Datenqualität und absolutes Vertrauen.
Mit dem Modern Data Warehouse können Benutzer komplexe Daten bereinigen und konsolidieren, die vor Ort oder in Azure SQL DB bereitgestellt werden. Das MDW bleibt vollständig anpassbar und unterstützt die komplexesten Umgebungen. So wird sichergestellt, dass Datenquellen schnell integriert und gereinigt werden können.
Business-Anwender erhalten Zugang zu Daten, denen sie vertrauen und die sie verstehen – ohne zeitraubendes Skripting.
Operational Data Exchange
Verbinden von sämtlichen Unternehmensdaten aus den unterschiedlichsten Quellen.
Mit dem Operational Data Exchange können Benutzer eine Verbindung zu über 100 Webanwendungen und Datenbanktypen herstellen und Zeitplanlasten in Azure Data Lake oder einer strukturierten Datenbank konfigurieren. Die Speicherung aller Daten in einem einzigen Format und an einem einzigen Ort bildet die Grundlage für jede Art von fortschrittlicher Analyse wie KI und maschinelles Lernen.
Die Stärke dieses Ansatzes liegt in der Fähigkeit, eine Verbindung zu den ständig wachsenden und sich ständig verändernden unterschiedlichen Arten von Datenquellen herzustellen. Das Ergebnis liefert dem Benutzer eine einzige Quelle, um die Verbindung/Zugriff zu den Ausgangsdaten herzustellen.

Die wichtigsten Features von TimeXtender
-
Datenherkunft:
Lückenlose Darstellung des Datenlebenszyklus, Nachverfolgung aller Objekte und deren Abhängigkeiten -
Auswirkungsanalysen
für Tabellen & Felder, Identifikation von Abhängigkeiten & potenziellen Auswirkungen -
Dokumentation:
Ausgabe des gesamten Metadatenmodell als PDF-Dateil, vollständige Versionskontrolle mitenthalten -
integrierte Sicherheitsfunktionen:
Benutzer & Zugriffsrechte identifizieren, Sicherheit auf Objekt- & Zeilenebene aktivieren -
Versionskontrolle:
automatische Generierung einer neuen Version, wenn ein Objekt erstellt, geändert oder gelöscht wird -
Multiple Umgebungen:
Unterstützung von mehreren dedizierten Umgebungen für Entwicklung, Test, Produktion -
Konnektoren:
Daten aus praktisch jeder Datenquelle verbinden und extrahieren
-
Performance Tracking:
Speicherung aller Ausführungszeiten bis hin zu den kleinsten Aufgaben -
Maschinelles Lernen:
Geschwindigkeit, Agilität & optimierte Leistung, Ausführung von mehreren Aufgaben parallel möglich -
Incremental load:
Umsetzung mit wenigen Klicks, um Ladezeiten zu reduzieren & Systemleistung zu verbessern -
Semantic layer:
einfacher Zugriff auf Daten, die für bestimmte Abteilung oder bestimmten Zweck relevant sind -
Dimensionsdaten:
Änderungen im Laufe der Zeit oder zu einem bestimmten Zeitpunkt genau bewerten -
mehrere User:
mehrere Personen können gleichzeitig an demselben Projekt arbeiten, Check-In- & Check-Out-Funktionen -
Integration von vorhandenen DWH:
vollständige Integration in die automatisierte Plattform problemlos möglich

